Python selenium基础用法详解
一、Python Selenium 简介和环境配置
1、Selenium简介
Selenium 是一套完整的web应用程序测试系统,包含了测试的录制(Selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。Selenium 支持的语言包括C#,Java,Perl,PHP,Python 和 Ruby。目前,Selenium Web 驱动程序最受 Python 和 C#欢迎。 Selenium 测试脚本可以使用任何支持的编程语言进行编码,并且可以直接在大多数现代 Web 浏览器中运行。
2、Selenium的安装
打开 cmd,输入下面命令进行安装。
1
pip install selenium
执行后,使用 pip show selenium 查看是否安装成功。
3、安装浏览器驱动
针对不同的浏览器,需要安装不同的驱动
Firefox 浏览器驱动:Firefox
Chrome 浏览器驱动:Chrome
Edge 浏览器驱动:Edge
推荐chrome谷歌浏览器作为模拟浏览器,因此还需要chromedriver作为驱动,但 Chrome 在用 selenium 进行自动化测试时还是有部分 bug ,常规使用没什么问题,但如果出现一些很少见的报错,可以使用 Firefox 进行尝试,毕竟是 selenium 官方推荐使用的。
现在,因为相应版本选择需要查看谷歌浏览器版本,在chrome浏览器上方地址栏输入:
1
chrome://settings/help
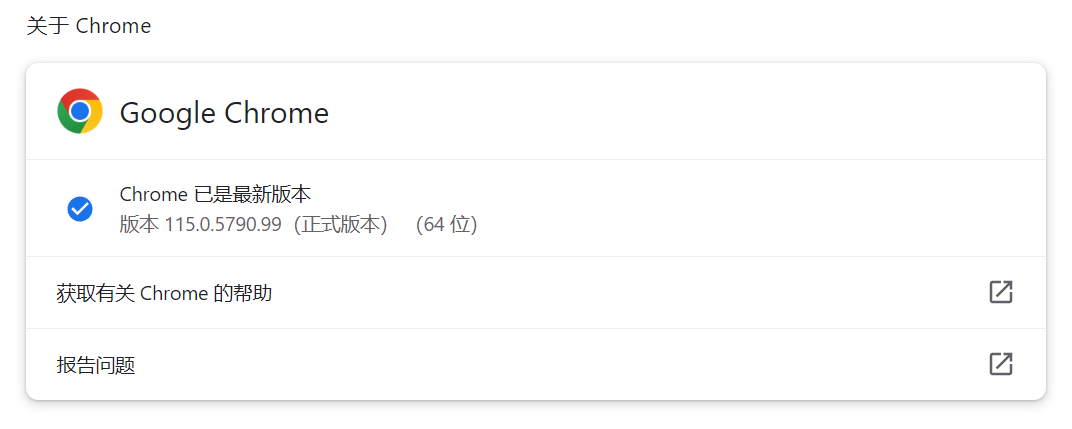
4、下载驱动
打开 Chrome驱动。单击对应的版本。
根据自己的操作系统,选择下载。
注意:WebDriver 需要和对应浏览器的版本对应,才能正常运行。
将 chromedriver.exe 保存到制定目录
- Windows系统:保存到Python的 Scripts 目录下
- MAC系统:保存到/usr/local/bin/
注意:这一步也可以不做,可以在使用时告知 WebDriver 所在的路径。
二、Python Selenium 基础操作
1、启动浏览器
启动 Chrome 浏览器
1
2
3
from selenium import webdriver
driver = webdriver.Chrome()
如果在配置开发环境时,没有将浏览器的 WebDriver 放到指定目录,可以告知 WebDriver 所在的路径。
1
2
3
from selenium import webdriver
driver = webdriver.Chrome(executable_path=r'.\chromedriver.exe')
2、元素定位
使用 selenium 定位页面元素的前提是你已经了解基本的页面布局及各种标签含义。要定位并获取页面中的信息,首先要使用 webdriver 打开指定页面,再去定位。元素的定位是自动化测试的核心,要想操作一个元素,首先应该识别它。
Selenium 提供了以下几种定位元素的方法:
| 描述 | 查找一个元素 | 查找多个元素 |
|---|---|---|
| 通过 ID 定位元素 | find_element_by_id() | find_elements_by_id() |
| 通过 Name 定位元素 | find_element_by_name() | find_elements_by_name() |
| 通过 XPath 定位元素 | find_element_by_xpath() | find_elements_by_xpath() |
| 通过完整链接文本定位超链接 | find_element_by_link_text() | find_elements_by_link_text() |
| 通过部分链接文本定位超链接 | find_element_by_partial_link_text() | find_elements_by_partial_link_text() |
| 通过标签名定位元素 | find_element_by_tag_name() | find_elements_by_tag_name() |
| 通过类名定位元素 | find_element_by_class_name() | find_elements_by_class_name() |
| 通过CSS选择器定位元素 | find_element_by_css_selector() | find_elements_by_css_selector() |
注意:查找一个元素的方法仅仅只返回第一个匹配上的元素,查找多个元素的方法会返回所有匹配上的元素。它们的使用方法基本一致。
假设页面元素如下所示(后面的部分参考代码会以此为基础进行说明):
1
2
3
4
5
6
7
8
9
10
11
12
13
<html>
<body>
<form id="loginForm">
<input name="username" type="text" />
<input name="password" type="password" />
<input name="continue" type="submit" value="Login" />
<input name="continue" type="button" value="Clear" />
</form>
<p class="content">Are you sure you want to do this?</p>
<a href="continue.html">Continue</a>
<a href="cancel.html">Cancel</a>
</body>
<html>
ID 定位
通过 ID 定位上面 id 为 loginForm 的 form 元素:
1
login_form = driver.find_element_by_id('loginForm')
name 定位
name 指定标签的名称,在页面中可不唯一。通过 Name 定位上面 name 为 username 的元素:
1
username = driver.find_element_by_name('username')
XPath 定位
XPath 是 XML 文档中查找结点的语法。因为 HTML 文档也可以被转换成 XML(XHTML)文档,Selenium 的用户可以利用这种强大的语言在 web 应用中定位元素。
通过 XPath 定位上面的 form 元素:
1
2
3
4
5
6
# 使用绝对定位(页面结构轻微调整,就会导致定位失败)
login_form = driver.find_element_by_xpath("/html/body/form[1]")
# HTML 页面中的第一个 form 元素
login_form = driver.find_element_by_xpath("//form[1]")
# id 为 loginForm 的第一个 form 元素
login_form = driver.find_element_by_xpath("//form[@id='loginForm']")
link文本定位
通过链接文本定位元素:
1
2
3
4
# 通过完整链接文本定位超链接
continue_link = driver.find_element_by_link_text('Continue')
# 通过部分链接文本定位超链接
continue_link = driver.find_element_by_partial_link_text('Conti')
tag名定位
1
login_form = driver.find_element_by_tag_name('form')
class 定位
class 指定标签的类名,在页面中可不唯一。通过类名定位第一个类(class)名为 content 的元素:
1
content = driver.find_element_by_class_name('content')
CSS 选择器定位
通过 CSS 选择器定位:
1
content = driver.find_element_by_css_selector('p.content')
3、Selenium 三种等待方式
现在的大多数的 Web 应用程序是使用Ajax技术。当一个页面被加载到浏览器时, 该页面内的元素可以在不同的时间点被加载。因此,有时候需要等待一些时间,让网页加载完全后再进行操作。
存在三种等待方法可使用,分别为:强制等待、隐式等待和显式等待。
强制等待
强制等待通过使用 time.sleep() 实现。不管浏览器是否加载完成,程序都等待设定的时间,时间一到,继续执行后面的代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
from selenium import webdriver
import time
driver = webdriver.Chrome()
url = 'https://android.myapp.com/myapp/search.htm?kw=QQ'
driver.get(url)
# 强制等待 5s 后再执行下一步
time.sleep(5)
element = driver.find_element_by_class_name('installBtn')
print(element.get_attribute('appname'))
driver.quit()
这种等待方式太过于死板,会严重影响程序执行速度。
隐式等待
隐式等待通过使用 implicitly_wait() 方法实现,默认等待时间是 0 秒。隐式等待是设置一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步;否则,一直等到时间截止,然后执行下一步。implicitly_wait() 的用法比 time.sleep() 更智能,前者是在一个时间范围内智能的等待,后者是智能等待一个固定的时间。
1
2
3
4
5
6
7
8
9
10
from selenium import webdriver
driver = webdriver.Chrome()
# 设置隐式等待时间,最长等待 10s
browser.implicitly_wait(10)
url = 'https://android.myapp.com/myapp/search.htm?kw=QQ'
driver.get(url)
element = driver.find_element_by_class_name('installBtn')
print(element.get_attribute('appname'))
driver.quit()
隐式等待仍然有一个弊端,那就是程序会一直等待整个页面加载完成,也就是一般情况下浏览器标签栏那个小圈不再转,才会执行下一步。就可能会出现这种情况:个别 js 之类的东西特别慢,即使我们想要定位的元素早就已经加载完成了,程序仍然会继续等待,直到整个页面加载完成或时间截止,然后执行下一步。
注意:隐式等待值的设置对 WebDriver 的整个生命周期有效,所以只要设置一次即可,不需要像
time.sleep()在每个地方都进行设置。
显式等待
显式等待是在代码中定义等待一定条件发生后再进一步执行你的代码。通过 WebDriverWait 结合 ExpectedCondition 实现。
实现逻辑是:程序每隔 XX 秒判断一下设定的条件,如果条件成立,则执行下一步;否则继续等待,直到超过设置的最长时间,然后抛出超时异常。显示等待包含了判断条件和最长等待时间。
实现步骤:首先初始化一个 WebDriverWait 实例;然后调用 until() 或 until_not()。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
url = 'https://android.myapp.com/myapp/search.htm?kw=QQ'
driver.get(url)
try:
# 判断类名为 installBtn 的元素是否被添加在 dom 树里面(并不代表该元素一定可见)
# 间隔 0.5 秒进行一次判断,直到条件成立或超过 10 秒。
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'installBtn')))
print(element.get_attribute('appname'))
finally:
driver.quit()
WebDriverWait 的初始化参数说明如下:
- driver: WebDriver 实例
- timeout: 超时时间,等待的最长时间
- poll_frequenc: 调用
until()或until_not()中的方法的间隔时间,默认是0.5秒 - ignored_exception: 忽略的异常,如果在调用
until()或until_not()的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException。
until() 表示预期条件成立,until_not() 表示预期条件不成立。它们的参数一样,说明如下:
- metho: 期望的条件,即在等待期间,每个一段时间被调用的方法
- message: 如果超时,抛出超时异常,将
message传入异常
expected_conditions 模块提供了一组预定义的条件给 WebDriverWait 使用(即可作为 until() 或 until_not() 中的 method 参数):
| 预期条件 | 说明 |
|---|---|
| title_is | 页面的标题是某内容 |
| title_contains | 页面的标题包含某内容 |
| url_to_be | 当前的 url 是否为指定的内容 |
| url_contains | 当前的 url 是否包含指定的内容 |
| url_matches | 当前的 url 是否符合提供的正则表达式。 |
| url_changes | 当前的 url 是否不是指定的内容 |
| visibility_of | 某元素出现在 DOM 树里面并可见 |
| visibility_of_element_located | 某元素出现在 DOM 树里面并可见 |
| visibility_of_all_elements_located | 定位某类元素,判断是否都可见。 如果都可见,返回所有元素;否则,返回 false。 |
| visibility_of_any_elements_located | 定位某类元素,判断是否可见。返回可见的所有元素。 |
| invisibility_of_element_located | 某元素不可见或没有出现在 DOM 树里面 |
| staleness_of | 判断某元素是否仍在 DOM 树,可判断页面是否已经刷新 |
| presence_of_element_located | 某元素出现在 DOM 树里面(不表示其是可见的), 如果存在的话,返回单个元素 |
| presence_of_all_elements_located | 某类元素出现在 DOM 树里面(不表示其是可见的), 如果存在的话,返回的是一个 list |
| text_to_be_present_in_element | 某个元素文本包含某文字 |
| text_to_be_present_in_element_value | 某个元素的值包含某文字 |
| element_to_be_clickable | 某元素是可见的,并且可点击 |
| element_to_be_selected | 某元素是可选择的 |
| element_located_selection_state_to_be | 定位某元素,判断某元素的选中状态是否等于给定的值 |
| element_located_to_be_selected | 定位某元素,判断是否被选中 |
| element_selection_state_to_be | 某元素的选中状态是否等于给定的值,可以用来判断选中或没选中 |
| alert_is_present | 出现一个弹框 |
| new_window_is_opened | 一个新的 window 被打开 |
| frame_to_be_available_and_switch_to_it | 某 frame 是可得到的,并已经切换为它 |
| number_of_windows_to_be | window 的数量是否等于一个指定的值 |
三种等待方式的比较
以下是三种等待方式的比较:
- 强制等待: 等待设定的时间,不管页面是否加载完成。在每个需要等待的地方都需要进行设置。
- 隐式等待: 在设定的时间范围内进行智能等待,直到页面加载完成或时间截止。在 WebDriver 对象的整个生命周期,只需要设置一次。
- 显式等待: 在设定的时间范围内进行智能等待,直到设定的条件满足或时间截止。隐式等待是固定判断页面是否加载完成,而显式等待可以根据需求设定判断的条件。
推荐尽量使用显式等待。可以提高代码运行效率。
4、操作元素
元素基础操作
一般来说,webdriver 中比较常用的操作元素的方法有下面几个:
| 方法 | 说明 |
|---|---|
| text | 属性值,元素的文本 |
| tag_name | 属性值,元素的标签名 |
| size | 属性值,元素的大小 |
| click() | 点击元素 |
| send_keys() | 在元素上模拟按键输入 |
| submit() | 提交元素的内容,如果可以的话 |
| clear() | 清除元素的内容,如果其是一个文本输入元素 |
| is_enabled() | 元素当前是否处于 enable 状态 |
| is_selected() | 元素当前是否处于被选中状态 |
| get_attribute() | 获取元素的属性值 |
| get_property() | 获取元素的属性值 |
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
driver = webdriver.Chrome()
url = 'https://www.baidu.com/'
driver.get(url)
# 定位“百度一下”的 button
search_btn = driver.find_element_by_id('su')
# 获取 button 元素的标签名和大小
print('tagName = {}, size = {}'.format(
search_btn.tag_name, search_btn.size))
# 获取 button 的enable 和选中状态
print('Enabled = {}, Selected = {}'.format(
search_btn.is_enabled(), search_btn.is_selected()))
# 获取 button 的类名属性
print('Class name = {}'.format(search_btn.get_attribute('class')))
# 定位搜索的输入框
search_input = driver.find_element_by_id('kw')
# 清除输入框中的内容
search_input.clear()
# 在输入框中模拟输入字符 “Selenium”
search_input.send_keys('Selenium')
# 执行搜索,有以下三种方法:
# a. 在输入框中模拟输入 “Enter” 按键
# search_input.send_keys(Keys.ENTER)
# b. 提交输入框的内容
# search_input.submit()
# c. 点击“百度一下” button
search_btn.click()
在某些情况下,我们可能需要模拟输入组合键,参考代码如下:
1
2
#ctrl+a 全选输入框内容
search_input.send_keys(Keys.CONTROL,'a')
填写表格(选择操作)
现在我们已经了解到可以通过 send_keys() 向文本框中输入文字,但是其他元素呢?我们可以对元素一个个进行单独操作,这不是一个好的方法。因此 WebDriver 提供了一个叫 Select 的类,可以完成这些操作。
| 方法 | 说明 |
|---|---|
| options | 属性,所有选择项 |
| all_selected_options | 属性,所有被选中的选择项 |
| first_selected_option | 属性,第一个被选中的选择项 |
| select_by_value() | 通过值选择对应选项 |
| select_by_index() | 通过索引选择对应选项 |
| select_by_visible_text() | 通过文本内容选择对应选项 |
| deselect_all() | 清除所有选择。仅当支持多选时有效 |
| deselect_by_value() | 通过值取消选择对应选项 |
| deselect_by_index() | 通过索引取消选择对应选项 |
| deselect_by_visible_text() | 通过文本内容取消选择对应选项 |
参考代码:
1
2
3
4
5
6
from selenium import webdriver
from selenium.webdriver.support.ui import Select
driver = webdriver.Chrome()
url = 'https://www.baidu.com/'
driver.get(url)
鼠标和键盘操作
WebDriver 通过 ActionChains 类提供了一些鼠标和键盘操作相关的方法:
| 方法 | 说明 |
|---|---|
| perform() | 执行所有存储在 ActionChains 中的操作 |
| reset_actions() | 清除所有存储在 ActionChains 中的操作 |
| click() | 在指定元素上进行点击操作。如果没有指定元素,在当前鼠标所在位置进行点击操作 |
| click_and_hold() | 在指定元素上按住鼠标左键 |
| context_click() | 在指定元素上进行鼠标右键点击操作。如果没有指定元素,在当前鼠标所在位置进行鼠标右键点击操作 |
| double_click() | 在指定元素上进行双击操作。如果没有指定元素,在当前鼠标所在位置进行双击操作 |
| drag_and_drop() | 在源元素上按住鼠标左键,然后移动到目标元素上并释放鼠标 |
| drag_and_drop_by_offset() | 在源元素上按住鼠标左键,然后移动指定偏移并释放鼠标 |
| key_down() | 只发送一个按键,而不释放它。其只能与辅助按键(control、Alt 和 Shift) |
| key_up() | 释放一个辅助按键 |
| move_by_offset() | 将鼠标从当前位置按照指定的偏移量进行移动 |
| move_to_element() | 将鼠标移动到指定元素的中间 |
| move_to_element_with_offset() | 将鼠标移动到指定元素的指定坐标上,元素的左上角坐标为(0, 0) |
| pause() | 暂定指定时间内的所有输入 |
| release() | 释放在指定元素上的按住操作 |
| send_keys() | 发送按键到当前被 focus 的元素 |
| send_keys_to_element() | 发送按键到指定的元素 |
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome()
url = 'https://www.baidu.com/'
driver.get(url)
# 定位“百度一下”的 button
search_btn = driver.find_element_by_id('su')
# 定位搜索的输入框
search_input = driver.find_element_by_id('kw')
# 首先,向文本输入框中模拟输入“Selenium”;
# 然后,点击“百度一下”按钮,开始进行搜索
ActionChains(driver)\
.send_keys_to_element(search_input, 'Selenium')\
.click(search_btn)\
.perform()
5、操作浏览器
浏览器基础操作
WebDriver 提供了一些操作浏览器的基本方法:
| 方法 | 说明 |
|---|---|
| minimize_window() | 最小化当前窗口 |
| maximize_window() | 最大化当前窗口 |
| set_window_size() | 设置当前窗口的大小 |
| back() | 控制浏览器后退 |
| forward() | 控制浏览器前进 |
| refresh() | 刷新当前页面 |
| close() | 关闭当前窗口,只关闭单个窗口 |
| quit() | 退出相关的驱动程序和关闭所有窗口 |
参考代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://www.baidu.com/')
# 最大化当前窗口
driver.maximize_window()
# 最小化当前窗口
driver.minimize_window()
# 设置当前窗口的宽度为 1080,高度为 800,单位为像素
driver.set_window_size(1080, 800)
# 控制浏览器后退
driver.back()
# 控制浏览器前进
driver.forward()
# 刷新当前页面
driver.refresh()
# 关闭当前窗口
driver.close()
# 退出相关的驱动程序和关闭所有窗口
driver.quit()
Frame 切换
在 Web 应用中会遇到 frame/iframe 表单嵌套页面的情况,WebDriver 只能在一个页面上对元素识别与定位,对于 frame/iframe 表单嵌套页面上的元素无法直接定位。WebDriver 提供了如下方法来进行 frame/iframe 之间的切换:
| 方法 | 说明 |
|---|---|
| switch_to.frame() | 切换到指定的 frame/iframe |
| switch_to.default_content() | 切换到默认的 frame/iframe |
窗口切换
在浏览器操作过程中,会存在多个窗口的情况,这时就需要进行窗口切换。WebDriver 提供了如下方法:
| 方法 | 说明 |
|---|---|
| current_window_handle | 属性,获取当前窗口的句柄 |
| window_handles | 属性,获取当前会话中的所有窗口句柄 |
| switch_to.window() | 切换到指定句柄的窗口 |
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from selenium import webdriver
driver = webdriver.Chrome()
url = 'https://www.baidu.com/'
driver.get(url)
# 获取当前窗口句柄
main_window = driver.current_window_handle
# 点击“关于百度”
link = driver.find_element_by_link_text('关于百度').click()
# driver.window_handles 可以获取当前会话中的所有窗口句柄
for handle in driver.window_handles:
if handle != main_window:
# 切换到指定句柄的窗口
driver.switch_to.window(handle)
break
操作弹窗
WebDriver 提供了对弹窗的处理。具体做法:首先,使用 WebDriver.switch_to.alert 获取到弹窗;然后,使用 text、accept()、dismiss() 和 send_keys() 等方法进行操作。
| 方法 | 说明 |
|---|---|
| text | 属性,返回弹窗中的文字信息 |
| accept() | 接受现有弹框 |
| dismiss() | 取消现有弹框 |
| send_keys() | 发送文本至弹框 |
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from selenium import webdriver
driver = webdriver.Chrome()
url = 'https://www.baidu.com/'
driver.get(url)
# 鼠标悬停至“设置”链接
link = driver.find_element_by_id('s-usersetting-top')
ActionChains(driver).move_to_element(link).perform()
# 打开搜索设置
driver.find_element_by_link_text("搜索设置").click()
time.sleep(2)
# 保存设置
driver.find_element_by_link_text("保存设置").click()
time.sleep(2)
# 获取弹框的文本
print(driver.switch_to.alert.text)
# 接受弹框
driver.switch_to.alert.accept()
# 取消弹框
# driver.switch_to.alert.dismiss()
本文参考