BGP简析
如果将网络世界的物理设备抽象为三种:计算节点,交换节点和路由节点,那么路由协议就是路由节点之间的数据通信,本文主要讲下边界网关协议BGP。BGP是互联网上一个核心的去中心化自治路由协议,这是一个用于互联网(Internet)上的路由协议,它的地位是核心的(目前是最重要的,互联网上唯一使用的路由协议),它的目的是去中心化,以达到各个网络自治。
路由协议划分
- AS(Autonomous system):自治系统,指在一个(有时是多个)组织管辖下的所有IP网络和路由器的全体(破除偏见:AS 不只有一个路由器)。对于互联网来说,一个AS是一个独立的整体网络。而BGP实现的网络自治也是指各个AS自治。每个AS有自己唯一的编号,其值范围从 1 到 65535。AS 编号 64512 到 65535 定义为私有 AS 编号。
- IGP(Interior Gateway Protocol):内部网关协议,在一个AS内部所使用的一种路由协议。一个AS内部也可以有多个路由器管理多个网络。各个路由器之间需要路由信息以知道子网络的可达信息。IGP就是用来管理这些路由。代表的实现有RIP和OSPF。
- EGP(Exterior Gateway Protocol):外部网关协议,在多个AS之间使用的一种路由协议,现在已经淘汰,被BGP取而代之。
- BGP(Border Gateway Protocol):BGP就是为了替换EGP而创建,它的地位与EGP相似。但是BGP也可以应用在一个AS内部。因此BGP又可以分为IBGP(Interior BGP :同一个AS之间的连接)和EBGP(Exterior BGP:不同AS之间的BGP连接)。IGP的协议是针对同一个AS网络来设计的,一个自治网络的规模一般都不大,所以设计的时候就没有考虑大规模网络的情况。而当一个自治网络足够大时,OSPF存在性能瓶颈。BGP本身就是为了在Internet工作,其设计就是为了满足大型网络的要求,所以大型私有IP网络内部可以使用IBGP。
- 总的来说,这几类路由协议,小规模私有网络IGP,大规模私有网络IBGP,互联网EBGP。
BGP名词
- BGP对等体:BGP对等体(peer)也叫BGP邻居,与OSPF、 RIP等协议不同,BGP的会话是基于TCP建立的。建立BGP对等体关系的两台路由器并不要求必须直连。BGP存在两种对等体关系类型:EBGP及IBGP。针对这两种对等体类型,BGP处理路由的操作存在较大差异。
- EBGP:EBGP(External BGP)是指位于不同自治系统(AS)的BGP路由器之间的BGP邻居关系。两台路由器之间要建立EBGP对等体关系,必须满足两个条件 :一是两个路由器所属AS不同(也即AS号不同);二是在配置BGP时,对等体IP地址要求路由可达,并且TCP连接能够正确建立 。
- IBGP:IBGP(Internal BGP)是指位于相同自治系统的BGP路由器之间的BGP邻接关系。两台路由器之间要建立IBGP对等体关系,必须满足两个条件:一是两个路由器所属AS需相同(也即AS号相同);二是在配置BGP时,对等体IP地址要求路由可达,并且TCP连接能够正确建立。
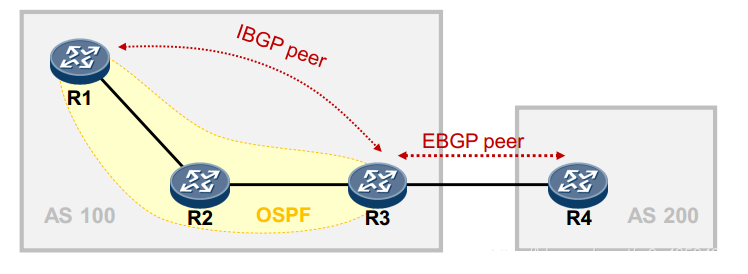
BGP 的产生
- 背景:自己有一个局域网(命名为LAN—A),一个路由器(命名为router-A)
- 若LAN—A里的主机想上外网/对外提供服务,向ISP(Internet service provider)申请一个公网ip,这里的ISP可以是联通,移动,电信等等,局域网主机可以通过router-A的NAT/PAT(Network / Port address translation)将自己的私网IP转换成这个公网IP,router-A上 将ISP router的地址设为默认路由。这样地址转换之后的IP包都发送到了ISP,进而发送到了互联网(这也是我们家用路由器能让家里的设备上网的原理),就可以上网了。此时不需要BGP。
- 若提供的对外服务非常多,同时既想访问联通、又想访问电信网络,但联通没那么多公网ip,那么向IANA 申请自己的公网ip池,组建自己的AS。此时,联通或者电信怎么知道申请的公网IP是什么?router-A的默认路由该设置到联通的ISP路由器,还是电信的?
- 通过BGP,可以将router-A的路由信息发送到联通,电信,这样ISP就知道了改如何访问自己的公网ip,也就是说我们普通的使用者通过ISP,能访问到LAN-A的主机。另一方面,通过在LAN-A运行BGP服务,可以管理router-A的默认路由。此时的LAN-A已经是 跟联通电信平起平坐的大网络了 。当然,这只是理论上,国内公有云也是要租公网ip的。
BGP协议
BGP可以说是最复杂的路由协议。它是应用层协议,其传输层使用TCP,默认端口号是179。因为是应用层协议,可以认为它的连接是可靠的,并且不用考虑底层的工作,例如fragment,确认,重传等等。BGP是唯一使用TCP作为传输层的路由协议,其他的路由协议可能都还到不了传输层。
TCP连接的窗口是65K字节,也就是说TCP连接允许在没有确认包的情况下,连续发送65K的数据。而其他的路由协议,例如EIGRP和OSPF的窗口只有一个数据包,也就是说前一个数据包收到确认包之后,才会发送下一个数据包。当网络规模巨大时,需要传输的数据也相应变大,这样效率是非常低的。这也是它们不适合大规模网络的原因。而正是由于TCP可以可靠的传输大量数据,且互联网的路由信息是巨大的,TCP被选为BGP的传输层协议,并且BGP适合大规模网络环境。
BGP报文
BGP的IP协议号为6。BGP报文由BGP报文头和具体报文内容两部分组成,BGP的运行是通过消息驱动的,共有5种报文类型,这些报文类型有相同的报文头。这些报文类型通过TCP协议进行传播(端口号是179)。消息最长为4096字节,最短为19字节。BGP报文头包括三的部分,总长19字节。
- Marker:占16字节,用于检查BGP对等体的同步信息是否完整,以及用于BGP验证的计算。不使用验证时所有比特均为1(十六进制则全“FF”)。
- Length:占2个字节(无符号位),BGP报文总长度(包括报文头在内),以字节为单位。长度范围是19~4096。
- Type:占1个字节(无符号位),BGP报文类型。Type有5个可选值,表示BGP报文头后面所接的5类报文。
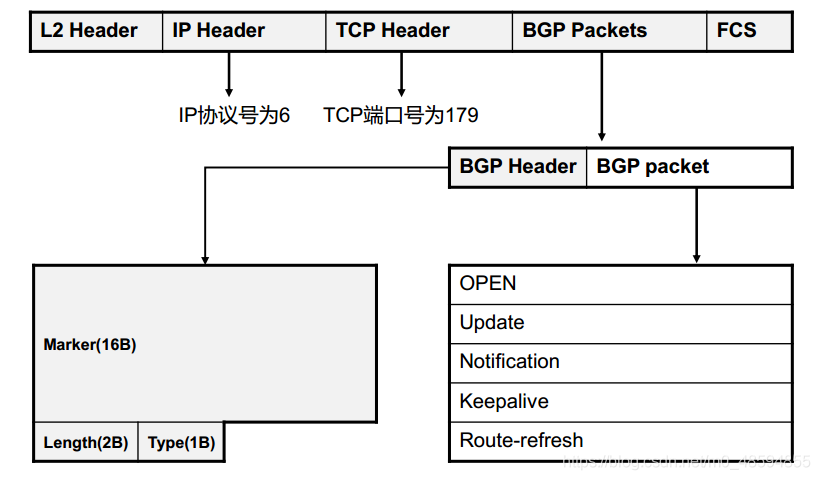
BGP的报文类型包括Open、Update、Notification、Keepalive和Route-refresh五种。
- Open:协商BGP参数,TCP连接建立之后,BGP发送的第一个包。收到Open之后,BGP peer会发送一个Keepalive消息以确认Open。其他所有的消息都只会在Open消息确认之后,并且BGP连接已经建立之后发送。
- Update:交换路由信息,BGP连接后的首次Update会交换整个BGP route table,之后的Update只会发送变化了的路由信息。所以说BGP是动态的传输路由消息的变化。
- Notification:差错通知,出错时发送的消息,这个消息一旦发送,BGP连接将会中断。
- Keepalive:保持邻居关系,没有data,只有header。用来保持BGP连接,通常是1/3的BGP session hold time。默认是60秒,如果hold time是0,不会发送Keepalive。
- Route-refresh:用于在改变路由策略后请求对等体重新发送路由信息。只有支持路由刷新能力的BGP设备会发送和响应此报文。当路由策略发生变化时,触发请求对等体重新通告路由。
每一种BGP数据的data都不相同,这些都由网络设备商实现了,简单看一下Open和Update的data吧。

BGP Open 数据,由于是发送的第一个包,因此就是一些配置信息。例如自身的AS号,BGP连接的超时时间(hold time),BGP id。
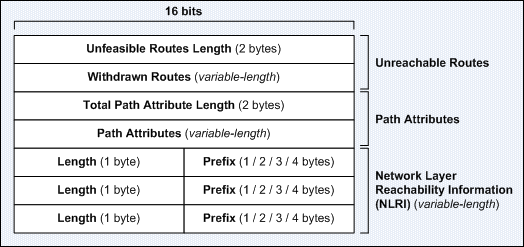
BGP Update 数据,主要就是交换Network Layer Reachability Information (NLRI)。一个Update数据包里面只会有一条path的路由信息,因此只有一组path attribute,但是路由可以有多条。具体的说,一个BGP router可能连接了多个BGP peer router,那么它在发送BGP Update数据时,一次只会发送一个它的BGP peer router的信息。
BGP状态机
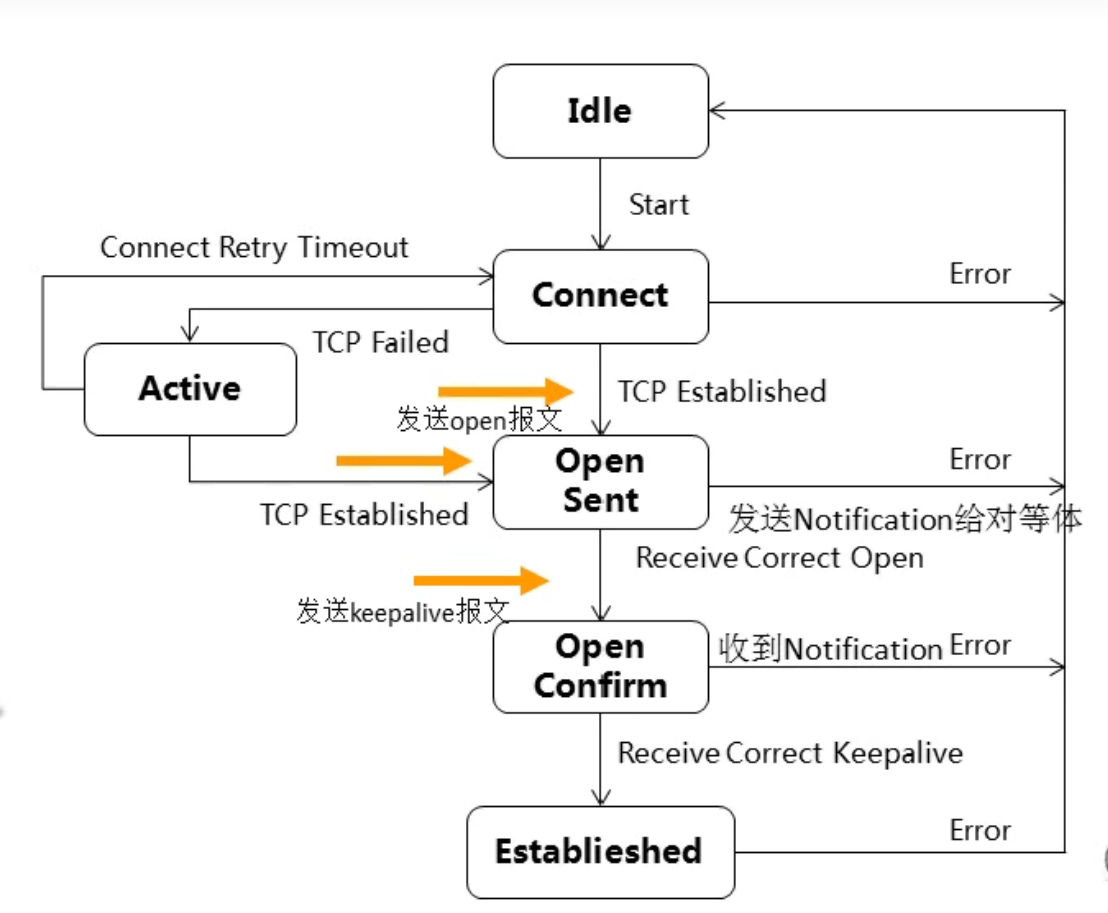
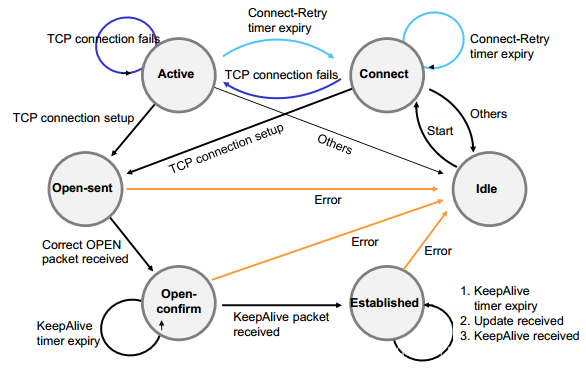
根据RFC4271协议规定,BGP的最小状态分为Idle、Connect、Active、OpenSent、OpenConfirm和Established(FRR为了流程更加完整,增加了Clearing和Deleted两种状态)。
- Idle(空闲):Idle 是BGP连接的第一个状态,在空闲状态,BGP在等待一个启动事件,启动事件出现以后,BGP初始化资源,复位连接重试计时器(Connect-Retry)(32s),发起一条TCP连接,同时转入Connect(连接)状态。
- Connect(连接):在Connect 状态,BGP发起第一个TCP连接,如果 连接重试计时器(Connect-Retry)超时,就重新发起TCP连接,并继续保持在Connect 状态,如果TCP 连接成功,就转入OpenSent 状态,如果TCP 连接失败,就转入Active 状态。(TCP连接失败两种情况:1.收到TCP参数协商失败的回复,则进入Active状态,2.对方长时间没有回复,超时,则保持在Connect状态—实验结果,如果想要实现这种效果,只需要把路由删除,那么对方就没有办法发送TCP回复)
- Active(活跃):在Active状态,BGP总是在试图建立TCP连接,如果连接重试计时器(Connect-Retry)超时,就退回到Connect 状态,如果TCP 连接成功,就转入OpenSent 状态,如果TCP 连接失败,就继续保持在Active状态,并继续发起TCP连接。(TCP连接失败两种情况:1.收到TCP参数协商失败的回复,则继续保持在Active状态,2.对方长时间没有回复,超时,才进入Connect状态—实验结果,如果想要实现这种效果,只需要在一个方向上删除peer就可以了。总结为,第一种情况,就保持在Active状态,第二种情况则保持在Connect状态)
- OpenSent(打开消息已发送):在OpenSent 状态,TCP连接已经建立,BGP也已经发送了第一个Open报文,剩下的工作,BGP就在等待其对等体发送Open报文。并对收到的Open报文进行正确性检查,如果有错误,系统就会发送一条出错通知消息并退回到Idle状态,如果没有错误,BGP就开始发送 Keepalive 报文,并复位Keepalive 计时器,开始计时。同时转入OpenConfirm状态。
- OpenConfirm(打开消息确认)状态:在OpenConfirm状态,BGP发送一个Keepalive报文,同时复位保持计时器,如果收到了一个Keepalive 报文,就转入Established 阶段,BGP邻居关系就建立起来了。如果TCP连接中断,就退回到Idle 状态。
- Established(连接已建立):在Established 状态,BGP 邻居关系已经建立,这时,BGP将和它的邻居们交换Update报文,同时复位保持计时器。
在除Idle 状态以外的其它五个状态出现任何Error 的时候,BGP状态机就会退回到Idle 状态。
另外,BGP协议还规定了13种events:
- BGP Start
- BGP Transport connection open
- BGP Transport connection closed
- BGP Transport connection open failed
- Receive OPEN message
- Receive OPEN CONFIRM message
- Receive KEEPALIVE message
- Receive UPDATE messages
- Receive NOTIFICATION message
- Holdtime timer expired
- KeepAlive timer expired
- Receive CEASE message
- BGP Stop
6个状态加上13种events共同构成了BGP的状态机。
BGP如何工作
BGP是一种路径矢量协议(Path vector protocol)的实现。因此,它的工作原理也是基于路径矢量。首先说明一下,下面说的BGP route指的是BGP自己维护的路由信息,区分于设备的主路由表,也就是我们平常看见的那个路由表。BGP route是BGP协议传输的数据,并存储在BGP router的数据库中。并非所有的BGP route都会写到主路由表。每条BGP route都包含了目的网络,下一跳和完整的路径信息。路径信息是由AS号组成,当BGP router收到了一条 路由信息,如果里面的路径包含了自己的AS号,那它就能判定这是一条自己曾经发出的路由信息,收到的这条路由信息会被丢弃。
这里把每个BGP服务的实体叫做BGP router,而与BGP router连接的对端叫BGP peer。每个BGP router在收到了peer传来的路由信息,会存储在自己的数据库,前面说过,路由信息包含很多其他的信息,BGP router会根据自己本地的policy结合路由信息中的内容判断,如果路由信息符合本地policy,BGP router会修改自己的主路由表。本地的policy可以有很多,举个例子,如果BGP router收到两条路由信息,目的网络一样,但是路径不一样,一个是AS1->AS3->AS5,另一个是AS1->AS2,如果没有其他的特殊policy,BGP router会选用AS1->AS2这条路由信息。policy还有很多其他的,可以实现复杂的控制。
除了修改主路由表,BGP router还会修改这条路由信息,将自己的AS号加在BGP数据中,将下一跳改为自己,并且将自己加在路径信息里。在这之后,这条消息会继续向别的BGP peer发送。而其他的BGP peer就知道了,可以通过指定下一跳到当前BGP router,来达到目的网络地址。
所以说,BGP更像是一个可达协议,可达信息传来传去,本地根据收到的信息判断决策,再应用到路由表。
BGP 协议特点
- 应用层协议,基于tcp。其它路由协议还到不了传输层,传输机制及单次数据量都赶不上tcp。这是BGP 适合大规模网络环境的重要原因。
- BGP: 一个更像应用程序的路由协议BGP工作于TCP 179号端口,与其说是路由协议,不如说是一个应用程序,一个用来互相分发路由信息的应用程序。tcp 是两个主机的通信,我们将运行 BGP 服务的主机/路由器成为 BGP router,与之相对的tcp 对端称为bgp peer(可以看到,peer是一个相对概念)。每个BGP router在收到了peer传来的路由信息,会根据policy 丢弃或存储在自己的数据库。
- BGP 协议有点像http2协议,有Open、Update、Notification和Keepalive几种类型,每种类型有自己的格式。BGP Open 数据,由于是发送的第一个包,因此就是一些配置信息。包括自身的AS号,BGP连接的超时时间(hold time),BGP id。
- BGP连接后的首次Update会交换整个BGP route table,之后的Update只会发送变化了的路由信息。
- RIP 路由信息中的路径是路由器地址链 (router1 -> router3 -> router2),BGP 路由信息中的路径是AS 地址链(AS2 -> AS1)
BGP在进行路由通告的时候,需要遵循以下原则:
- 多条路径时,BGP Speaker只选最优的给自己使用(负载均衡和FRR除外)。
- BGP Speaker只把自己使用的路由(最优路由)通告给相邻体。
- BGP Speaker从EBGP获得的路由会向自己所有BGP相邻体通告(包括EBGP和IBGP)。
- BGP Speaker从IBGP获得的路由不向自己的IBGP相邻体通告(反射器除外)。
- BGP Speaker从IBGP获得的路由是否通告给自己的EBGP相邻体要根据IGP和BGP同步的情况来决定。
- 当收到对端的refresh报文并且本端邻居支持refresh能力,BGP Speaker将把自己所 有BGP路由通告给对等体。
- GR过程中,主备倒换方在GR结束时BGP Speaker会把自己所有BGP路由通告给对等体。 这些规则的来龙去脉 参见 BGP Basics: Internal And External BGP
BGP协议的路径属性
当一条BGP路由被BGP路由器通告给其对等体时,这条BGP路由会携带多个路径属性值(Path Attributes)并传递给对等体。 这些路径属性,将影响BGP的路由优选,使得BGP的路由策略能力异常强大。
BGP路径属性分为公认属性和可选属性。公认属性是所有BGP协议实现必须都能正确识别的属性;可选属性是BGP协议实现可不支持的属性。公认属性又分为公认必遵和公认自决属性。可选属性分为可选传递和可选非传递。
- 公认必遵是在update报文中必须携带的属性(例如:Origin、AS_Path、Next_hop)。
- 公认自决并不要求必须包含在update报文中(例如:Local-Preference)。
- 可选传递必须在报文接收到包含该属性的路由后,将属性传递给其他对等体(例如:Community)。
- 可选非传递即使在收到该属性的路由,可不支持也可不传递该属性给其他对等体(例如:MED)。
Origin
Origin属于公认必遵属性,表示BGP路由的起源。根据路由被引入BGP的方式不同,存在三种类型的Origin:igp、egp和incomplete。当去往同一个目的地存在多条不同Origin属性的路由时,在其他条件都相同的情况下,BGP将按Origin:IGP > EGP > Incomplete的顺序优选路由。
| 名称 | 标记 | 描述 |
|---|---|---|
| igp | i | 通过BGP network通告的路由 |
| egp | E | 通过EGP这种早期的协议重发布而来 |
| incomplete | ? | 通过import命令,从其他协议引入到BGP的路由 |
AS_Path
AS_Path属于公认必遵属性,是前往目标网络的路由经过的AS号列表,该属性有两个作用,一是确保路由在EBGP对等体之间传递不会出现环路;二是作为路由优选的衡量标准之一。路由在被通告给EBGP对等体时,路由器会在该路由的AS_Path中追加上本地的AS号;路由被通告给IBGP对等体时,AS-path不会发生改变。
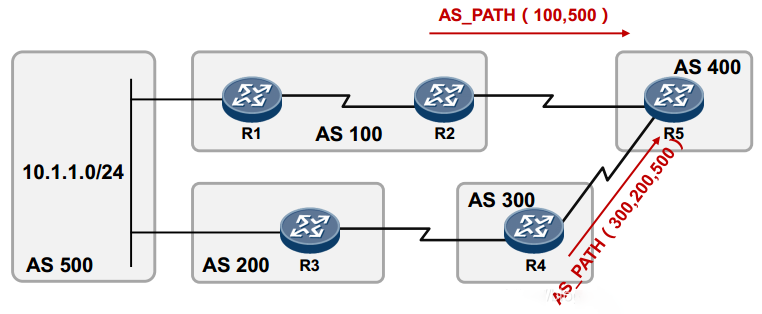
AS_Path的重要作用之一便是影响BGP路由的优选,在上图中,R5同时从R2及R4学习到去往10.1.1.0/24网段的BGP路由,在其他条件相同的情况下,R5会优选R2通告的路由,因为该条路由的AS_Path属性值较短,也即AS号的个数更少。
AS_Path类型
AS_Path分为四种类型:AS_SET、AS_SEQUENCE、AS_CONFED_SEQUENCE和AS_CONFED_SET。
- AS_SET指去往目标网络需要经过路径的无序AS号列表,一般用于指示汇总路由
- AS_SEQUENCE指去往目标网络需要经过路径的有序AS号列表
- AS_CONFED_SEQUENCE指去往目标网络需要经过路径的有序AS本地联邦号列表
- AS_CONFED_SET指去往目标网络需要经过路径的无序AS本地联邦号列表
Next_hop
下一跳(Next_hop)属于公认必遵属性,用于指定到达目标网络的下一跳地址 。当路由器学习到BGP路由后,需对BGP路由的Next_hop属性值进行检查,该属性值(IP地址)必须在本地路由可达,如果不可达,则这条BGP路由不可用。
缺省情况下,路由器将BGP路由通告给自己的EBGP对等体时,将该路由的Next_hop设置为自己的更新源IP地址 ,但是如果路由的Next_Hop地址值与EBGP对等体(更新对象)同属一个网段,那么该条路由的Next_Hop地址将保持不变并传递给它的BGP对等体
另外,在将路由传递给自己的IBGP对等体时,也会保持路由的Next_hop属性值不变 ,这就会出现一种情况,就是IBGP对等体与下一跳属性的IP地址网络不可达,为了避免出现这样的情况,可以通过next-hop-self变更next-hop属性。
Local-Preference
Local_Preference又叫本地优先级属性,属于公认自决属性,用于告诉AS中的路由器,哪条路径是离开AS的首选路径。
缺省的Local_Preference值为100,Local_Preference属性值越大则BGP路由优先级越高。这里的Local指的是AS内部,因此该属性只能被传递给IBGP对等体,而不会传递给EBGP对等体。本地使用network命令引入、重发布引入和EBGP更新的路由可将该属性的默认值(100)发给IBGP对等体,FRR可通过bgp default local-preference来修改默认值,set local-preference可以为路由策略设置独立的Local-Preference。
Community
Community属于可选传递属性,是一种路由标记,类似于一种标签,能对路由进行分类,用于简化路由策略的执行。有了Community属性,我们可以为不同种类的路由打上不同的Community属性值,这些属性值会随着BGP路由更新给其他对等体,那么在其他对等体上,只需要根据Community属性值来执行差异化的策略即可。
Community属性值长度为32个比特,也就是4个字节,可用十进制表示,也常用(AS号:编号),其中AS号是高位2字节,编号是低位2字节。
FRR给出了Well-Known的Community值,具体可参考Community
| Community | 描述 | 描述 |
|---|---|---|
| no-advertise | 路由不会传递给其他对等体 | 通过BGP network通告的路由 |
| no-export | 路由不会传递给EBGP对等体(联邦除外) | 通过EGP这种早期的协议重发布而来 |
| no-export-subconfed | 路由不会传递给EBGP对等体(包括联邦) | 通过import命令,从其他协议引入到BGP的路由 |
MED
MED(Multi Exit Discriminator)属于可选非传递属性,用于向外部对等体指出进入本AS的首选路径,即当进入本AS的入口有多个时,AS可以使用MED动态地影响其他AS选择进入的路径。MED属性值越小则BGP路由越优。MED主要用于在AS之间影响BGP的选路。 MED被传递给EBGP对等体后,对等体在其AS内传递路由时,携带该MED值,但将路由传递给其EBGP对等体时,缺省不会携带MED属性。
缺省情况下,路由器只比较来自同一相邻AS的BGP路由的MED值,也就是说如果去往同一个目的地的两条路由来自不同的相邻AS,则不进行MED值的比较。
BGP路由反射器
背景
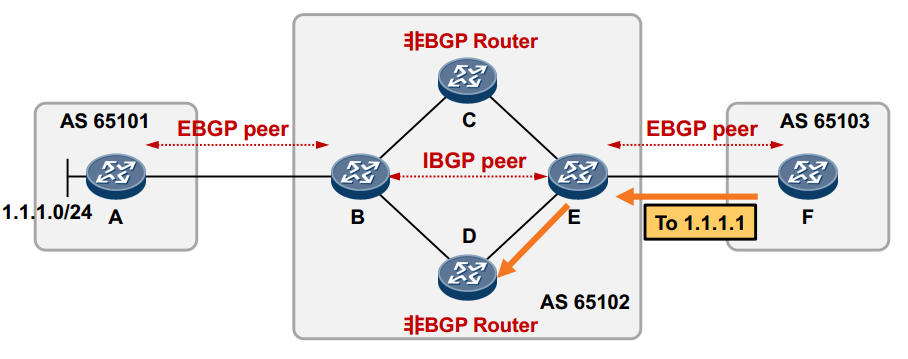
在中转AS65102中,BCDE路由互通。B与E运行BGP,并且两者建立IBGP对等体关系(两者并非直连,但是对于BGP,这是允许的,仅需确保两者之间能够正确建立TCP连接即可)。C与D并未运行BGP。 此时A将本地路由1.1.1.0/24通告到BGP,最终F能够通过BGP学习到该条路由。 但是C、D由于并未运行BGP,因此无法通过BGP学习到1.1.1.0/24路由。如此一来,F发往1.1.1.0/24网络的数据包在到达C/D后将被丢弃,在C及D路由器这里,就出现了路由黑洞。
水平分割
为了使得BGP路由能够正常交互,我们就不得不在该传输AS内所有路由器上都运行BGP,且构建全互联的IBGP对等体关系。但是这样也引入了一个问题,就是如何防环。我们知道BGP路由在AS之间的防环依赖于AS_Path路径属性,当路由器收到BGP路由后,发现该路由所携带的AS_Path属性中出现了其自己所处的AS号,则路由器认为出现了路由环路,它将忽略该条路由。AS_Path属性仅在路由离开AS时才会被更改,而BGP路由在AS内部传递时,路由的AS_Path属性值不会发生改变,如此一来,IBGP路由的防环就无法依赖AS_Path。为了防止BGP路由在AS内部传递时发生环路,BGP规定路由器不能将自己从IBGP对等体学习到的路由再传递给其他IBGP对等体,这就是IBGP水平分割规则。
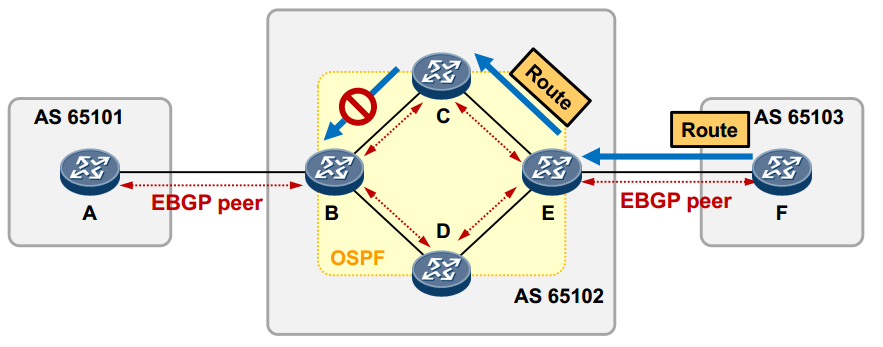
上图中,C从E学习到的IBGP路由,由于水平分割规则的限制,不能够传递给B路由器,这将导致B无法学习到F通告的BGP路由。所以由于IBGP水平分割原则的存在,BGP要求AS内须保证IBGP对等体关系的全互联,因为只有这样,才能够确保每一个路由器都能学习到路由。然而在AS内的所有BGP路由器之间维护全互联(full-mesh)的IBGP对等体关系是需要耗费大量资源的,一方面路由器需维护大量的TCP及BGP连接,尤其在路由器数量较多时,另一方面网络的可扩展性、可维护性也非常差。为了解决这一问题,BGP提出了两个解决方案:路由反射器(RR)和BGP联邦。
路由反射器(RR)原理
路由反射器就像一面镜子,将自己学习到的IBGP路由“反射”出去,使得IBGP路由得以在AS内传递。当然,反射器并不是将所有的IBGP路由都进行反射,它将遵循一定的规则。将一台BGP路由器指定为反射器的同时,还需要指定其Client。至于Client本身,无需做任何配置,而且它并不知晓反射器在网络中的存在。
路由反射器规定了三个角色:反射器、Client和非Client。反射器在接收到BGP路由后,会遵循这样的规则
- 如果该路由学习自非Client IBGP对等体,则反射给自己所有的Client;
- 如果路由学习自Client,则反射给所有非Client IBGP对等体和除了该Client之外的所有Client;
- 如果路由学习自EBGP对等体,则发送给所有Client和非Client IBGP对等体。
在这三条规则中,出现了两种行为:发送和反射。发送指的是传统情况下(相当于RR不存在的场景下)的BGP路由传递行为,而反射指的是遵循路由反射规则的情况下,RR执行的路由传递动作,被反射出去的路由会被RR插入特殊的路径属性Originator_ID和Cluster_List,用来防止环路和进行路由优选。
Originator_ID
Originator_ID是一个可选非传递属性,属性类型为9。是一个32bit的数值。RR将一条BGP路由进行反射时会在反射出去的路由中增加该路径属性,其值被设置为以下这些路由器的BGP Router-ID:
如果路由为本地AS始发:则Originator_ID被设置为BGP路由宣告者的Router-ID;
如果路由为非本地AS始发:则Originator_ID被设置为本地AS的边界路由器的Router-ID。
如果AS内存在多个RR,则Originator_ID属性由第一个RR创建,并且不被后续的RR所更改。
当BGP路由器收到一条携带Originator_ID属性的IBGP路由,并且Originator_ID属性值与自身的Router-ID相同,则它会忽略关于该条路由的更新。同时,Originator_ID及属性将会影响路由优选的决策。

Cluster_List
BGP路由反射器定义了一个概念路由反射簇(Cluster),路由反射簇包括反射器RR及其Client。一个AS内允许存在多个路由反射簇。
每一个簇都有唯一的簇ID(Cluster-ID,缺省时为RR的BGP Router-ID)。 当一条路由被反射器反射后,该RR(该簇)的Cluster_ID就会被添加至路由的Cluster_list属性中。 当RR收到一条携带Cluster_list属性(可选非传递)的BGP路由,且该属性值中包含该簇的Cluster_ID时,RR认为该条路由存在环路,因此它将忽略关于该条路由的更新。
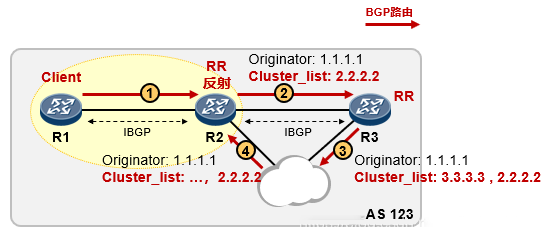
R2收到BGP路由后,发现该路由携带着Cluster_List属性,并且该属性的值包含与本地的Cluster_ID相同的Cluster_ID ,则意识到出现了路由环路,因此忽略关于该路由的更新。
换句话说,Cluster_list用于非始发反射器的环路识别;Originator_ID用于边界和始发反射器的环路识别。
BGP联邦
BGP联邦原理
BGP联邦是对IBGP对等体之间的关系进行重新的划分,分为联邦IBGP和联邦EBGP。联邦IBGP和联邦EBGP遵循IBGP和EBGP的路由通告规则,这样就可以把原本受限于IBGP水平分割规则而不能接收的路由通告到联邦EBGP对等体。
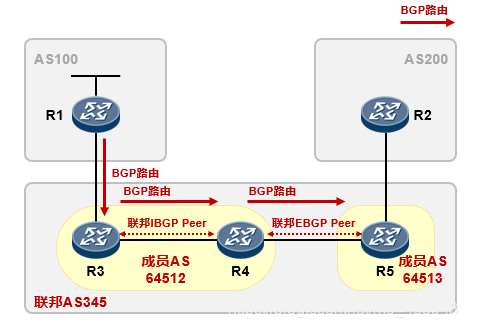
上图中,原先R3、R4和R5属于同一个IBGP对等体,根据水平分割原则,R3和R5没法收到R2和R1通告的路由。现将R3、R4和R5重新规划为BGP联邦,其中R3和R4同属于一个联邦IBGP,R4和R5属于联邦EBGP对等体关系。如此一来,由于R4和R5变成了特殊的EBGP对等体关系,那么两者的BGP路由就能相互传递,从而解决水平分割带来的问题。
联邦内BGP路由的路径属性遵循以下规则
- 通告给联邦的BGP路由,Next_Hop属性在整个联邦范围内缺省不会发生改变;
- 通告给联邦的BGP路由,MED属性在整个联邦范围内缺省不会发生改变;
- 通告给联邦的BGP路由,Local_Preference属性在整个联邦范围内缺省不会发生改变;
BGP路由在联邦内的EBGP对等体间传递时,路由器将成员AS号插入AS_Path,并且使用AS_CONFED_SEQUENCE和AS_CONFED_SET(详见AS_Path类型)的特殊AS_Path存储。成员AS号不会被公布到联邦AS之外,也即对于联邦AS外部而言,联邦成员AS是不可见的。AS_Path中的联邦成员AS号用于在联邦内部避免环路;联邦内成员AS号不参与AS_Path长度计算。
配置BGP联邦
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
router bgp 100 vrf ns1
bgp router-id 10.10.1.2
neighbor 10.10.1.4 remote-as 345
!
address-family ipv4 unicast
network 4.0.1.0/24
exit-address-family
!
#ns2的联邦成员号为64512
router bgp 64512 vrf ns2
bgp router-id 10.10.1.4
#ns2的AS号和联邦AS号为345
bgp confederation identifier 345
neighbor 10.10.1.2 remote-as 100
#ns2要连接的对等体20.10.1.6,联邦成员号为64512
neighbor 20.10.1.6 remote-as 64512
neighbor 20.10.1.6 update-source 20.10.1.4
!
address-family ipv4 unicast
neighbor 20.10.1.6 next-hop-self
exit-address-family
!
#ns3的联邦成员号为64512
router bgp 64512 vrf ns3
bgp router-id 20.10.1.6
#ns3的AS号和联邦AS号为345
bgp confederation identifier 345
#ns3要连接的对等体联邦成员号为64513
bgp confederation peers 64513
neighbor 20.10.1.4 remote-as 64512
#ns3要连接的对等体30.10.1.8,联邦成员号为64513
neighbor 30.10.1.8 remote-as 64513
neighbor 30.10.1.8 update-source 30.10.1.6
!
address-family ipv4 unicast
neighbor 30.10.1.8 next-hop-self force
exit-address-family
!
#ns4的联邦成员号为64513
router bgp 64513 vrf ns4
bgp router-id 30.10.1.8
#ns4的AS号和联邦AS号为345
bgp confederation identifier 345
#ns4要连接的对等体联邦成员号为64512
bgp confederation peers 64512
#ns4要连接的对等体30.10.1.6,联邦成员号为64512
neighbor 30.10.1.6 remote-as 64512
!
address-family ipv4 unicast
neighbor 30.10.1.6 next-hop-self
exit-address-family
!
BGP路由优选
当BGP设备学习到去往同一个目的网络(包括网段和掩码)的多条BGP路由(路径)时,设备将这些路由都装载到BGP路由表,并在这些条目中进行路由优选,最终决策出最优(Best)的路由,将该BGP路由加载到全局路由表中,作为数据转发的依据 。当存在多路径时,BGP只会将其选择出来的最优路由通告给其他对等体。
BGP定义了一系列路由优选规则,从而使得设备能够在多条路由中选择出最优的路由。BGP在选择路由时严格按照先后顺序比较路由的属性,如果通过当前的属性就可以选出最优路由,BGP将不再进行后面的比较。由于BGP的选路规则与BGP路径属性相关,而通过路由策略可以调整路径属性,这就使得BGP拥有了十分灵活的路由操控能力。
- 优选具有最大Weight的路由
FRR通过neighbor PEER weight WEIGHT命令可以为对等体设置默认的路由权重,权重高的路由将被优选。 - 优选具有最大Local_Preference的路由
Local_Preference会在IBGP对等体之间传递,不会再EBGP对等体传递,参考Local-Preference - 优选起源于本地的路由
在其他条件相同的情况下,本地生成的路由优先级高于从邻居学来的路由。本地生成的路由包括- 静态路由static
- 汇总路由aggregates
- 重发布路由redistributed
- network引入的路由
- 优选AS_Path最短的路由
AS_Path长度最短的路由将被优选,AS_Path长度计算有以下规则:- AS_Set的长度为1,无论AS_Set中包括多少AS号,长度都当做1来计算。
- AS_confed_seq和AS_confed_set类型默认不参与AS_Path长度计算,除非使用命令bgp bestpath as-path confed。
- Origin(IGP > EGP > Incomplete)
根据路径属性Origin来优选路由,IGP > EGP > Incomplete - 优选MED最小的路由
MED(Multi Exit Discriminator)是一种度量值,MED属性值越小则BGP路由越优。一般情况下,BGP设备只比较来自同一AS(不同对等体)路由的MED属性值。可以通过配置命令来允许BGP比较来自不同AS的路由的MED属性值。执行bgp always-compare-med命令后,系统将比较来自不同AS中的对等体相同前缀路由的MED值。 - 优选EBGP对等体所通告的路由
EBGP对等体通告的路由优先级高于IBGP - 优选到Next_Hop的IGP度量值最小的路由
IGP度量值又叫IGP cost,指的是到达某个路由所指的目的地址的代价。cost一般是由OSPF引入,OSPF的cost默认值是10。 - BGP路由负载分担
大型网路中,到达同一目的地通常会存在多条有效BGP路由,设备只会优选一条最优的BGP路由,将 该路由加载到路由表中使用,并且只将最优路由发布给对等体,这一特点往往会造成很多流量负载不均衡的情况。 通过配置BGP负载分担,可以使得设备同时将多条等价的BGP路由加载到路由表,实现流量负载均衡,减少网络拥塞。值得注意的是,尽管配置了BGP负载分担,设备依然只会在多条到达同一目的地的BGP路由中优选一条路由,并只将这条路由通告给其他对等体。BGP负载分担默认不使能,需要通过命令bgp bestpath as-path multipath-relax来使能。对于IBGP对等体,只要开启BGP路由负载分担,向其他IBGP对等体通告路由时,总是使能next-hop-self选项。 - 优选已被选择的路由
当收到两条前置条件一样的路由,优先选择已有被优选通告的路由,这样可以避免出现路由振荡。如果配置了bgp bestpath compare-routerid则忽略这个优选规则。 - 优选Router-ID最小的BGP对等体发来的路由
如果配置了反射器,则使用Originator_ID代替Router-ID来进行比较。 - 优选Cluster_List最短的路由
Cluster_List属性参考路由反射器Cluster_List - 优选Peer-IP地址最小的对等体发来的路由
Peer-IP指的是通过neighbor命令配置对等体时所指定的IP地址。Peer-IP值越小,路由将被优先选择。
FRR的BGP路由策略
路由策略的实现分为两个步骤:
- 定义规则:定义将要实施路由策略的路由信息的特征,即定义一组匹配规则。可以用路由信息中的不同属性作为匹配依据进行设置,如目的地址、发布路由信息的路由器地址等。
- 应用规则:将匹配规则应用于路由的发布、接收和引入等过程的路由策略中。
过滤器
路由策略的核心内容是过滤器,通过使用过滤器,可以定义一组匹配规则。提供了以下几种过滤器供路由策略使用。
| 过滤器 | 应用范围 | 匹配条件 |
|---|---|---|
| 访问控制列表(ACL) | 各动态路由协议 | 入接口、源或目的地址、协议类型、 源或目的端口号 |
| 地址前缀列表(IP-Prefix List) | 各动态路由协议 | 源地址、目的地址、下一跳 |
| AS路径过滤器(AS-Path-Filter) | BGP协议 | AS路径属性 |
| 团体属性过滤器 (Community-Filter) | BGP协议 | 团体属性 |
| 扩展团体属性过滤器 (Extcommunity-Filter) | VPN | 扩展团体属性 |
| RD属性过滤器 (RouteDistinguisher-Filter) | VPN | RD属性 |
| Route-Policy | 各动态路由协议 | 目的地址、下一跳、度量值、 接口信息、路由类型、ACL、 地址前缀列表、AS路径过滤器、团体属性过滤器、 扩展团体属性过滤器和RD属性过滤器等。 |
其中,ACL、地址前缀列表、AS路径过滤器、团体属性过滤器、扩展团体属性过滤器和RD属性过滤器只能对路由进行过滤,不能修改通过过滤的路由的属性。而Route-Policy是一种综合过滤器,它可以使用ACL、地址前缀列表、AS路径过滤器、团体属性过滤器、扩展团体属性过滤器和RD属性过滤器这六种过滤器作为匹配条件来对路由进行过滤,并且可以修改通过过滤的路由的属性。下面对过滤器一一介绍。
FRR提供了基于IP,基于Community和基于AS-PATH的三种类型过滤器来匹配路由。
IP Access List
基于IP的路由ACL规则,比较少使用,通常是用IP Prefix List来设置策略。
1
2
3
4
5
6
7
8
9
10
11
12
access-list NAME [seq (1-4294967295)] permit IPV4-NETWORK
access-list NAME [seq (1-4294967295)] deny IPV4-NETWORK
#NAME:规则名称
#seq:规则序列号,不填则在上一个规则序列号基础上加5,若存在则加10,以此类推
#permit(deny):允许通过还是拒绝通过
#IPV4-NETWORK: ipv4网络
#example
access-list filter deny 10.0.0.0/9
access-list filter permit 10.0.0.0/8
access-list filter seq 13 permit 10.0.0.0/7
IP Prefix List
IP Prefix List提供了强大的基于IP前缀的过滤机制,除了access list之外,还能够基于ip掩码和ip掩码区间进行过滤。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
ip prefix-list NAME (permit|deny) PREFIX [le LEN] [ge LEN]
ip prefix-list NAME seq NUMBER (permit|deny) PREFIX [le LEN] [ge LEN]
no ip prefix-list NAME #取消io前缀规则
show ip prefix-list NAME #显示ip前缀规则
#NAME:规则名称
#seq:规则序列号,不填则在上一个规则序列号基础上加5,若存在则加10,以此类推
#permit(deny):允许通过还是拒绝通过
#PREFIX: ip前缀
#le LEN:匹配小于LEN的ip前缀
#ge LEN:匹配大于LEN的ip前缀
#example
ip prefix-list pl-allowed-adv seq 5 permit 82.195.133.0/25
ip prefix-list pl-allowed-adv seq 10 deny any
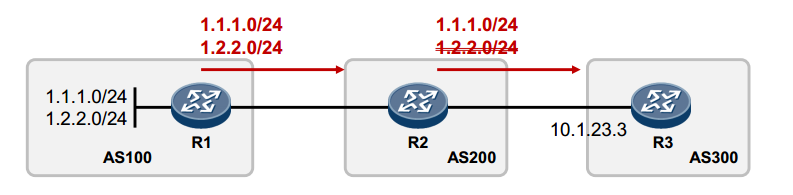
R2向R3通告BGP路由时,只过滤掉1.2.2.0/24路由,其他路由放行
1
2
3
4
5
#只列出和prefix-list相关命令
ip prefix-list 1 deny 1.2.2.0/24
ip prefix-list 1 permit any
router bgp 200
peer 10.1.23.3 prefix-list 1 out #out表示往外发送的方向;
Community-list
Community属性值是一种路由标记 ,FRR提供了基于Community的路由过滤方法。
1
2
3
4
5
6
7
8
9
10
11
bgp community-list [standard|expanded] NAME permit|deny COMMUNITY
no bgp community-list [standard|expanded] NAME
show bgp community-list [NAME detail]
#standard:COMMUNITY是一个确切值
#expanded:COMMUNITY可为正则表达式,都不填则由系统自动识别
#permit|deny:过滤规则
#example
bgp community-list 70 permit 7675:70
bgp community-list 70 deny
as-path access-list
as-path access-list是基于as-path的过滤规则,能够使用正则表达式对as-path进行过滤。
1
2
3
4
5
6
7
8
9
bgp as-path access-list WORD permit|deny LINE
#WORD:列表号
#LINE:正则表达式
#example
bgp as-path access-list 99 permit _0_
bgp as-path access-list 99 permit _23456_
bgp as-path access-list 99 permit _1310[0-6][0-9]_|_13107[0-1]_
其他过滤器
访问控制列表(ACL)
访问控制列表ACL(Access Control List)是一系列过滤规则的集合,可以称之为规则组。在每个规则组中,所有过滤规则是具有前后顺序的。用户在定义过滤规则时,根据报文的入接口、源或目的地址、协议类型、源或目的端口号等属性描述过滤规则,同时指定了拒绝或接收报文。之后,系统根据过滤规则对到达路由器的报文进行分类,并判断报文被拒绝或者接收。
ACL本身只是一组规则的集合,它只是通过过滤规则对报文进行了分类,因此ACL需要与路由策略配合使用,才能实现过滤报文的功能。
ACL包括针对IPv4路由的ACL和针对IPv6路由的ACL。按照ACL用途,ACL可以分为3种类型:基于接口的ACL(Interface-based ACL)、基本ACL(Basic ACL)和高级ACL(Advanced ACL)。用户在ACL中指定IP地址和子网范围,用于匹配路由信息的源地址、目的网段地址或下一跳地址。
在网络设备中(可以是接入设备、核心设备等)部署ACL特性,可以保障网络的安全性与稳定性。例如:
- 防止对网络的攻击,例如防止针对IP报文、TCP报文、ICMP(Internet Control Message Protocol)报文的攻击。
- 对网络访问行为进行控制,例如控制企业网中内网和外网的通信,用户访问特定网络资源,特定时间段内允许对网络的访问。
- 限制网络流量和提高网络性能,例如限定网络上行、下行流量的带宽,对用户申请的带宽进行收费,保证高带宽网络资源的充分利用。
地址前缀列表(IP-Prefix List)
地址前缀列表是一种包含一组路由信息过滤规则的过滤器,用户可以在规则中定义前缀和掩码范围,用于匹配路由信息的目的网段地址或下一跳地址。地址前缀列表可以应用在各种动态路由协议中,对路由协议发布和接收的路由信息进行过滤。
地址前缀列表和ACL相比,配置简单,应用灵活。但是当需要过滤的路由数量较大,且没有相同的前缀时,配置地址前缀列表会比较繁琐。
地址前缀列表包括针对IPv4路由的IPv4地址前缀列表和针对IPv6路由的IPv6地址前缀列表,IPv6地址前缀列表与IPv4地址前缀列表的实现相同。地址前缀列表进行匹配的依据有两个:掩码长度和掩码范围。
- 掩码长度:地址前缀列表匹配的对象是IP地址前缀,前缀由IP地址和掩码长度共同定义。例如,10.1.1.1/16这条路由,掩码长度是16,这个地址的有效前缀为16位,即10.1.0.0。
- 掩码范围:对于前缀相同,掩码不同的路由,可以指定待匹配的前缀掩码长度范围来实现精确匹配或者在一定掩码长度范围内匹配。
团体属性过滤器(Community-Filter)
团体属性过滤器是一组针对BGP路由的团体属性进行过滤的规则。在BGP的路由信息中,携带有团体属性(Community),团体属性是一组有相同特征的目的地址的集合,因此基于团体属性定义一些过滤规则,就可以实现对BGP路由信息的过滤。
除了使用公认的团体属性外,用户还可以自行定义数字型的团体属性。团体属性过滤器的匹配条件可以使用团体号或者正则表达式。
扩展团体属性过滤器(Extcommunity-Filter)
扩展团体属性过滤器是一组针对BGP的扩展团体属性进行过滤的规则。BGP的扩展团体属性常用的有如下几种:
VPN-Target扩展团体属性:VPN Target属性主要用来控制VPN实例之间的路由学习,实现不同VPN实例之间的隔离。VPN Target属性分为出方向和入方向,PE在发布VPNv4(Virtual Private Network version 4)或VPNv6(Virtual Private Network version 6)路由到远端的MP-BGP(Multi-protocol Extensions for Border Gateway Protocol)对等体时,会携带出方向VPN Target属性。远端MP-BGP对等体收到VPNv4或VPNv6路由后,会根据本地VPN实例的入方向VPN Target属性是否与路由所携带的VPN Target匹配,来决定哪些路由能被复制到本地VPN实例的路由表中。
SoO(Source of Origin)扩展团体属性:VPN某站点(Site)有多个CE接入不同的PE时,从CE发往PE的路由可能经过VPN骨干网又回到了该站点,这样很可能会引起VPN站点内路由循环。此时,针对VPN站点配置SoO属性可以区分来自不同VPN站点的路由,避免路由循环。
VPN-Target扩展团体属性和SoO扩展团体属性在格式上是一致的。扩展团体属性过滤器的匹配条件可以使用扩展团体号或者正则表达式。
RD属性过滤器(Route Distinguisher-Filter)
RD属性过滤器是一组针对VPN路由的RD属性进行过滤的规则。VPN实例通过路由标识符RD(Route Distinguisher)实现地址空间独立,区分使用相同地址空间的IPv4和IPv6前缀。RD属性过滤器针对不同RD指定匹配条件
Route-Policy
Route-Policy是一种比较复杂的过滤器,它不仅可以匹配给定路由信息的某些属性,还可以在条件满足时改变路由信息的属性。Route-Policy可以使用前面6种过滤器定义自己的匹配规则。
路由策略
FRR的路由策略通过设置Route Maps来实现。Route Maps一共可分为五个模块,分别是Matching Conditions(条件匹配)、Set Actions(策略设置)、Matching Policy(条件策略)、Call Action(跳转)和Exit Policy(结束策略)。
1
2
3
4
route-map ROUTE-MAP-NAME (permit|deny) ORDER
#ROUTE-MAP-NAME: 策略名称
#permit|deny:条件策略Matching Policy
#ORDER:策略匹配排序
Matching Conditions
Matching Conditions主要是基于过滤器对策略的适用范围进行圈定,可过滤的命令包括
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#匹配ACL
match ip|ipv6 address ACCESS_LIST
#匹配IP Prefix List
match ip|ipv6 address prefix-list PREFIX_LIST
#匹配Community-list
match community COMMUNITY_LIST
#匹配as-path access-list
match as-path ACCESS_LIST
#匹配其他路由参数
match ip|ipv6 address prefix-len 0-32
match ip|ipv6 next-hop address IPV4_ADDR|IPV6_ADDR
match metric METRIC
match local-preference METRIC
match peer IPV4_ADDR|IPV6_ADDR
#ZEBRA匹配
match source-protocol PROTOCOL_NAME
match source-instance NUMBER
Set Actions
Set Actions决定策略的生效方式,通过修改路由属性来影响路由策略,可设置的路由属性包括
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#设置路由参数
set ip next-hop IPV4_ADDRESS
set ip next-hop peer-address
set ip next-hop unchanged
set ipv6 next-hop peer-address
set ipv6 next-hop prefer-global
set ipv6 next-hop global IPV6_ADDRESS
set ipv6 next-hop local IPV6_ADDRESS
[no] set distance DISTANCE
set weight WEIGHT
#设置BGP协议属性
set local-preference LOCAL_PREF
set local-preference +LOCAL_PREF
set local-preference -LOCAL_PREF
set as-path prepend AS_PATH
set community COMMUNITY
set origin ORIGIN <egp|igp|incomplete>
set metric METRIC #即MED
#设置路由写入哪个路由表
set table (1-4294967295)
#设置标签(相当于Linux的域reaml)
set tag TAG
Matching Policy
Matching Policy包括permit和deny
permit表示如果路由条目匹配(Matching Conditions来判断),则执行Set Actions,然后接收该路由或者执行Exit Policy。
deny表示如果路由条目匹配(Matching Conditions来判断),则拒绝接收该条路由。
注意:route-map默认Matching Policy是deny,也就是说如果Matching Conditions没有匹配到,那么路由默认将会被拒绝,因此在设置route-map时,一般会在最后加入一条permit规则
Call Action
Call Action由Set Action调用,表示调用其他RouteMap策略。如果返回deny,则拒绝接收;返回permit则继续往下执行Matching Policy和Exit Policy,一般用于配置多个route-map。
Exit Policy
Exit Policy由next和goto N两个语法组成,next执行下一条规则,goto是跳到规则N后顺序执行。
路由汇总
BGP支持对路由条目进行汇总,并将汇总后的路由发送给其他对等体
路由衰减
路由不稳定的主要表现形式是路由振荡(Route Flapping),即路由表中的某条路由反复消失和重现。
发生路由振荡时,路由器就会向邻居发布路由更新,收到更新报文的路由器需要重新计算路由并修改路由表。所以频繁的路由振荡会消耗大量的带宽资源和CPU资源,严重时会影响到网络的正常工作。
路由衰减(Route Dampening)用来解决路由不稳定的问题。多数情况下,BGP协议都应用于复杂的网络环境中,路由变化十分频繁。为了防止持续的路由振荡带来的不利影响,BGP使用路由衰减来抑制不稳定的路由。
BGP衰减使用惩罚值(Penalty Value)来衡量一条路由的稳定性,惩罚值越高则说明路由越不稳定。路由每发生一次振荡,BGP便会给此路由增加一定的惩罚值(路由从激活状态变为未激活状态,惩罚值增加1000,路由在激活状态,收到新的路由更新,惩罚值加500)。当惩罚值超过抑制阈值(Suppress Value)时,此路由被抑制,不加入到路由表中,也不再向其他BGP对等体发布更新报文。
被抑制的路由每经过一段时间,惩罚值便会减少一半,这个时间称为半衰期(Half-life)。当惩罚值降到再使用阈值(Reuse Value)时,此路由变为可用并被加入到路由表中,同时向其他BGP对等体发布更新报文。上文提到的惩罚值、抑制阈值和半衰期都可以手动配置。BGP衰减的处理过程如下图所示。
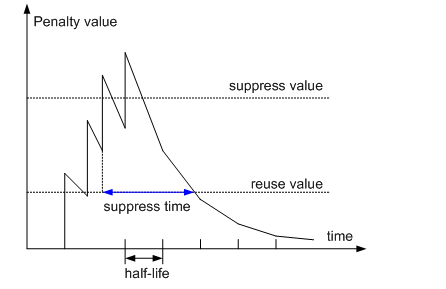
路由衰减只适用于EBGP路由。对于从IBGP收来的路由不能进行衰减,因为IBGP路由经常含有本AS的路由,内部网络路由要求转发表尽可能一致,IGP快速收敛就是为了达到信息同步,转发一致。如果衰减对IBGP路由起作用,不同路由器的衰减参数不一致时,会导致转发表不一致。
本文参考